1. 最短で検索する手順
- 検索語を入力します。
- データセットを選びます(タイトルのみ / タイトル+読み / 日本語→各言語)。
- タイトル検索を押します。
- 必要に応じて表示件数・並び順を変えます。
既定はランダム順なので、毎回違う発見系の見え方になります。順序を固定したいときは並び順を「タイトル」または「読み」に切り替えてください。
2. データセットの違い
- タイトルのみ: タイトル1列。軽量でシンプルな検索向け。
- タイトル+読み: 日本語タイトルに加えて読みがな検索ができます。
- カテゴリ: 日本語版 Wikipedia のカテゴリ名一覧。読みがなはありません。
- リダイレクト: 日本語版 Wikipedia のリダイレクト(別名・旧称)一覧。
- 日本語→各言語: 日本語タイトルと各言語タイトルの2列。各言語側の検索にも対応。
「日本語→各言語」データセットでは、画面の2つ目の検索ボタンが各言語検索として動作します。
逆に各言語検索で「Soseki」を入力すると、日本語タイトル側を探せます。
3. 検索の使い分け
- タイトル検索: まずはこれでOK。通常のキーワード検索です。
- 読み検索: 「タイトル+読み」で、読みがなから探したいときに使います。
- 各言語検索: 「日本語→各言語」で各言語タイトルを軸に探したいときに使います。
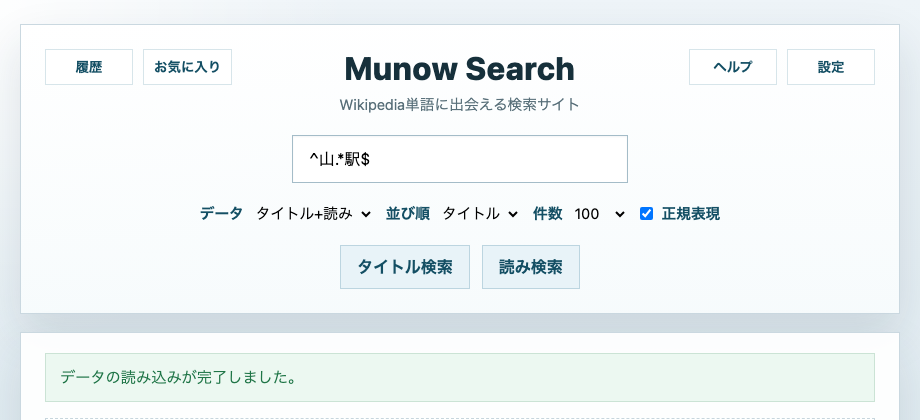
- 正規表現: 詳細条件で絞り込みたい上級者向けです。
- 読み検索: 「とうきょう」で「東京」を探す
- 英語検索: 「Mount Fuji」で「富士山」を探す
- 正規表現: `^山.*駅$` で「山」で始まり「駅」で終わる語を抽出
4. よくあるつまずき(確認ポイント)
- データ読み込みエラー: ブラウザを再読み込みし、ネットワーク接続を確認してください。
- 特定データセットが出ない: optional データセットが無効判定されると、プルダウンから自動で非表示になります。
- 正規表現が失敗する: パターンが長すぎる・重すぎる場合は安全のため中断されます。通常検索へ切り替えて再試行してください。
- `.*` のような広すぎる式は重くなりやすい
- まずは通常検索で語を絞ってから、必要なときだけ正規表現に切り替えると安定します
5. 補助機能
- 履歴: 最近の検索語を保存し、すぐ再検索できます(最大30件)。
- お気に入り: 気になった語を保存して後から見返せます(最大30件)。
- 並び順: 既定はランダム。タイトル順・読み順にも切り替えできます。
履歴やお気に入りに残した検索 URL は、開いたときの並び順設定に従って結果が並びます。 既定はランダムなので「保存したのに毎回違う並びで出る」と感じることがあります。 同じ並びで再現したい場合は、保存・共有する前に並び順を「タイトル」または「読み」に切り替えてください。
検索ボックスを空にしたまま「ランダム」並び順でタイトル検索ボタンを押すと、データセット全体からランダムに件数分が表示されます。 毎回違う発見を楽しみたいときの使い方です。
6. リダイレクト検索
データプルダウンで「リダイレクト」を選ぶと、日本語 Wikipedia のリダイレクト(別名・旧称)を検索できます。 他のデータセットと同じ検索ボックス・ボタンを使い、ボタンの役割だけが切り替わります。
- リダイレクト元検索: 1 つ目のボタン。別名(リダイレクト元タイトル)側を対象に検索します。旧称や略称から本来の記事を探したいときに使います。
- リダイレクト先検索: 2 つ目のボタン。本来のタイトル(リダイレクト先タイトル)側を対象に検索します。「この記事への別名はどれくらいあるか」を見るときに便利です。
例: 同じデータで「東京駅」と入力 → 「リダイレクト先検索」を押すと、「東京駅」へ向かう別名(「とうきょうえき」「Tokyo Station」など)が一覧表示されます。
結果カードはタイトル+読み形式と同じ 2 列レイアウトです(左: リダイレクト元 / 右: リダイレクト先)。両カラムとも日本語版 Wikipedia へのリンクになります。
7. カテゴリ検索
データプルダウンで「カテゴリ」を選ぶと、日本語版 Wikipedia のカテゴリ名一覧から検索できます。 「タイトルのみ」と同じ仕組みで、読みがなはありません。
- カテゴリ名そのものを「タイトル検索」または正規表現で絞り込めます。
- 読みがなを持たないため、読み検索ボタンは無効になります。
例: 正規表現 `^日本の.*駅$` で「日本の」で始まり「駅」で終わるカテゴリ名を抽出できます。
8. 発見のヒント(サジェストチップ)
検索ボタンの下に「発見のヒント」として複数のチップが並んでいます。クリックするだけで、そのチップに対応した検索条件(キーワード・データセット・正規表現フラグ・並び順)が自動的にセットされて検索が実行されます。初めて使う方が「こんな検索ができる」を体験するための入口です。
- 難読漢字: 「鵺」「麒麟」「翡翠」「髑髏」などの難読漢字をそのまま入力して検索するチップ。漢字タイトルの件数感を体感できます。
- 読み仮名で探す: 「ふじ」「さくら」などの読みがなで検索するチップ。「タイトル+読み」データセットの読み検索モードが自動で有効になります。
- 正規表現:
^山.*駅$(山で始まり駅で終わる)、^佐藤(佐藤で始まる)、.*神社$(神社で終わる)など、正規表現パターンのチップ。正規表現チェックボックスが自動で有効になります。 - 多言語: 「ペルシア語訳: 日本」「英語訳: 富士山」など、日本語→各言語データセットで検索するチップ。データセットの切り替えも自動で行われます。
daily モード(?daily=YYYYMMDD)で表示中は、通常のサジェストチップの代わりに「今日の単語」チップが表示されます(次節参照)。
9. 今日の単語(デイリー固定 URL)
URL に ?daily=YYYYMMDD(または ?daily だけ)を付けてアクセスすると、その日付に固定された 5 件の発見系チップが「発見のヒント」欄に表示されます。同じ日付であれば誰がアクセスしても同じ 5 件が出るので、SNS でシェアして「今日の出会い」を共有できます。
- 日付指定:
?daily=20260428で特定日を表示。 - 当日:
?dailyや?daily=todayで日本標準時(JST)の今日に解決。 - 5 件は「ランダムな Wikipedia タイトル × 3 件(タイトル+読みデータセットで動作。タイトルは部分一致検索のため切り詰め: 漢字のみなら先頭 2 文字 / それ以外は先頭 3 文字)」「正規表現の検索例(100 種類の単純な接尾/接頭マッチプールから日付ごとに 1 件)」「日本語→各言語の検索例(100 語の著名な日本語固有名詞プールから日付ごとに 1 語)」の組み合わせで構成され、それぞれ日付シードから決定論的に選ばれます。
- 並び順は固定(タイトル 3 件 → 正規表現 → 各国言語訳)で、内容のみが日付シードで決定論的に切り替わります。
- 表示中のチップをクリックすると、その条件で検索が走ります。データセット・正規表現フラグ・並び順(常に「ランダム」)が自動で切り替わります。
?daily=...パラメータは保持されたままなので、ブラウザの戻る/リンクの再訪でも同じ 5 件に戻れます。
10. 検索結果のシェア
検索結果上部のチップ列の右側にある「検索結果を共有」ボタンを押すと、シェア用のダイアログが開きます。検索条件・データセット・並び順・「今日の単語」指定が URL に含まれるため、まったく同じ画面を相手に共有できます。
- X / LINE / Facebook 円形ボタン: 該当 SNS の投稿画面を URL(とページタイトル)付きで新規タブに開きます。
- メール / メッセージ 円形ボタン: 既定のメールクライアント(
mailto:)または SMS アプリ(sms:)を URL とタイトル付きで起動します。 - URL 表示欄 + コピー: 共有 URL を表示します。「コピー」ボタンでクリップボードへコピーされ、トーストで通知されます。
- 閉じる: 右上の × ボタン、背景クリック、または ESC キー。